Month: September 2025

From Collection to Discovery: Why Processing Takes Time
From Collection to Discovery: Why Processing Takes Time
By MaryKay Severino

If you mailed us a little microSD card for Eclipse Soundscapes, you might be wondering: what happened after it left your hands? Why did processing take over a year? The short answer: scale and complexity.
Think about it.
- Nearly 1,000 AudioMoth devices were registered across both eclipses (219 in 2023 and 770 in 2024).
- Over 600 microSD cards were mailed back (126 in 2023 and 477 in 2024), each with hours of audio.
- Two eclipses happened only about six months apart, which meant we were still receiving and logging 2023 data while also updating protocols, training new volunteers, and preparing free kits for 2024.
- Some cards came with carefully written notes about time and location, while others had only online notes, only handwritten notes, both, or none at all. That mix made every envelope a surprise, sometimes a complete package and sometimes a puzzle to solve.
When plans met reality
In 2023, things were fairly straightforward on paper. We had not yet invited people to use their own devices, so most returns came in the standardized envelopes we provided, each clearly marked with an ES ID. Even so, sorting took longer than expected. We had originally planned for about 50 sites in 2023 and 200 in 2024, but so many people were excited to join that we expanded both years. That surge meant every microSD card had to be carefully logged by hand, checking whether we had the card itself, the online location info, and any written notes. We worked hard to be transparent by releasing several shared “data dashboard” spreadsheets on the website and posting social media reminders to check them. These updates let participants know what we had on file for them, but the process was still manual work, card by card.
 By 2024, when volunteers were invited to purchase and use their own AudioMoths, participation grew even bigger and the returns became more varied. Instead of neat, uniform envelopes, we began receiving packages of all shapes and sizes, many without an ES ID on the outside. Matching each one to online or handwritten notes added another layer of complexity and time.
By 2024, when volunteers were invited to purchase and use their own AudioMoths, participation grew even bigger and the returns became more varied. Instead of neat, uniform envelopes, we began receiving packages of all shapes and sizes, many without an ES ID on the outside. Matching each one to online or handwritten notes added another layer of complexity and time.
Device prep behind the scenes
For the 2023 annular eclipse, we prepped and mailed 219 kits before the event (64 for ES partners and team, 155 free kits). These devices were shipped with batteries uninstalled, which meant participants had to set the device’s internal clock themselves. That turned out to be more complicated than expected and also revealed that some AudioMoths might malfunction.
 Between 2023 and 2024, we ran battery usage tests to see if we could set the clocks and install batteries before mailing and still have enough battery power left by eclipse day. The answer was yes. That change made things easier for volunteers in 2024, but it also added more work for the ES team. While we were still receiving and processing 2023 data, we were preparing and mailing 390 additional free kits for 2024. Each device had its time manually set before mailing, in addition to batteries installed.
Between 2023 and 2024, we ran battery usage tests to see if we could set the clocks and install batteries before mailing and still have enough battery power left by eclipse day. The answer was yes. That change made things easier for volunteers in 2024, but it also added more work for the ES team. While we were still receiving and processing 2023 data, we were preparing and mailing 390 additional free kits for 2024. Each device had its time manually set before mailing, in addition to batteries installed.
 One thing remained consistent in both years: every AudioMoth required a firmware update, which had to be performed one by one by connecting the device to a computer. We also logged each device’s serial number, manually assigned an ES ID, and labeled the device in both written and braille formats.
One thing remained consistent in both years: every AudioMoth required a firmware update, which had to be performed one by one by connecting the device to a computer. We also logged each device’s serial number, manually assigned an ES ID, and labeled the device in both written and braille formats.
Beyond the devices themselves, we also provided everything a Data Collector might need, so it was as easy as possible to focus on the science of data collection. Each kit was assembled by hand with return labels, bags, and zip ties, and packaged one by one. This careful preparation was time-consuming but essential for keeping everything organized and supporting volunteers.
Two eclipses, back to back
It was incredibly exciting that the 2023 annular and 2024 total eclipses happened so close together. The 2023 eclipse gave us the chance to test our protocols for the first time, then immediately improve them for 2024. But it also meant the timelines overlapped. While we were still receiving and logging annular data, we were also reviewing what went well for Apprentices, Observers, and Data Collectors in 2023, updating trainings, preparing free kits, and making improvements for the total eclipse. The quick turnaround left us with some catching up to do once the 2024 data began arriving.
Training improvements took time

After the 2023 annular eclipse, we carefully reviewed what went right and what could be better across all three roles: Apprentice, Observer, and Data Collector. That review directly shaped some big changes for 2024. In addition to having complete instructions on the website, we added more live Q and A sessions, more live trainings, and quick tips that went out weekly in the days and weeks before the total eclipse. These changes helped Data Collectors feel supported and prepared (and also improved training for ES Observers), but the careful review and the work to build new materials also took time.
We began receiving cards in October 2023, with huge influxes in the two months after the 2023 annular eclipse and again after the 2024 total eclipse. The last wave arrived at the end of 2024, leaving us with a mountain of data ready to process.
What happens behind the scenes
 Processing was not just opening envelopes. It took custom computer programs written by the ES team to check every recording for a timestamp. If a device malfunctioned or was never set to the right time, we reviewed the Data Collector’s handwritten notes to determine the time and time zone. All times then had to be converted to UTC.
Processing was not just opening envelopes. It took custom computer programs written by the ES team to check every recording for a timestamp. If a device malfunctioned or was never set to the right time, we reviewed the Data Collector’s handwritten notes to determine the time and time zone. All times then had to be converted to UTC.
 We also had to calculate the exact eclipse times for each site, based on latitude and longitude. Some people entered this information online, others wrote it by hand, and some used formats that did not match the guidance we provided. That meant our team often converted locations by hand, corrected missing negatives in coordinates, and double checked any site that appeared in the middle of the ocean.
We also had to calculate the exact eclipse times for each site, based on latitude and longitude. Some people entered this information online, others wrote it by hand, and some used formats that did not match the guidance we provided. That meant our team often converted locations by hand, corrected missing negatives in coordinates, and double checked any site that appeared in the middle of the ocean.
![]() To keep participants in the loop, we regularly updated a public “data dashboard” spreadsheet that showed what we had received for each site, including microSD cards, online notes, and written notes. Social media posts pointed people back to this dashboard so they could confirm their information. We also shared maps of sites and a feedback form where participants could flag errors or confirm details. Each case was resolved one by one, with as many fixes made as possible.
To keep participants in the loop, we regularly updated a public “data dashboard” spreadsheet that showed what we had received for each site, including microSD cards, online notes, and written notes. Social media posts pointed people back to this dashboard so they could confirm their information. We also shared maps of sites and a feedback form where participants could flag errors or confirm details. Each case was resolved one by one, with as many fixes made as possible.
![]() In total, five custom programs were developed to handle audio data, mapping, eclipse timing, and other tasks. All of this code, along with full documentation, will be released publicly on GitHub by the end of 2026.
In total, five custom programs were developed to handle audio data, mapping, eclipse timing, and other tasks. All of this code, along with full documentation, will be released publicly on GitHub by the end of 2026.
 It was a bit like receiving thousands of puzzle pieces from hundreds of different puzzle boxes. Each piece matters, but first we had to sort them into the right box before we could put the bigger picture together.
It was a bit like receiving thousands of puzzle pieces from hundreds of different puzzle boxes. Each piece matters, but first we had to sort them into the right box before we could put the bigger picture together.
Why your effort mattered
Even if your recording did not end up in the final published analysis, your participation still mattered. Every card, every note, and every attempt helped us refine the process and build one of the most extensive eclipse sound archives ever created, which is on track to be publicly available by the end of 2026. You helped prove that a project of this scale is possible.
Explore the full journey
Want to see exactly how data moves from envelopes on our desks to public access on Zenodo? Check out the Data Processing Stages section of the Your Data in Action page. There you will find the full flowchart and a plain language explanation of how we move data from collection to discovery.
👉 Your Data in Action: Processing Stages

How Artificial Intelligence Might Shape the Future of Eclipse Soundscapes Data
How Artificial Intelligence Might Shape the Future of Eclipse Soundscapes Data
By MaryKay Severino and Henry "Trae" Winter
 It’s hard to avoid hearing about how Artificial Intelligence (AI) is changing the way we live and work. Today, the word AI is used to describe many different kinds of computer programs that can learn and help machines solve tough problems, sometimes with human help and sometimes completely on their own. Organizations are working to keep up with the rapid changes in AI tools, best practices, and questions about ethics. Both researchers and managers are taking these changes seriously and are figuring out how to best use AI in NASA’s mission to share the exploration of the universe around us.
It’s hard to avoid hearing about how Artificial Intelligence (AI) is changing the way we live and work. Today, the word AI is used to describe many different kinds of computer programs that can learn and help machines solve tough problems, sometimes with human help and sometimes completely on their own. Organizations are working to keep up with the rapid changes in AI tools, best practices, and questions about ethics. Both researchers and managers are taking these changes seriously and are figuring out how to best use AI in NASA’s mission to share the exploration of the universe around us.
 Members of the Eclipse Soundscapes (ES) team recently attended a NASA open data repositories workshop that prompted us to consider how AI might impact the Eclipse Soundscapes Project, even as it comes to an end. AI is starting to influence many areas of research and data sharing. One way that AI might impact large datasets, like the 500+ ES audio datasets, is by helping future researchers find, process, and analyze large amounts of data more efficiently and effectively.
Members of the Eclipse Soundscapes (ES) team recently attended a NASA open data repositories workshop that prompted us to consider how AI might impact the Eclipse Soundscapes Project, even as it comes to an end. AI is starting to influence many areas of research and data sharing. One way that AI might impact large datasets, like the 500+ ES audio datasets, is by helping future researchers find, process, and analyze large amounts of data more efficiently and effectively.
This raised an important question for us: How might these very near-future AI possibilities impact the way we share the audio data collected by ES Data Collectors during the 2023 Annular Eclipse and the 2024 Total Solar Eclipse? Here is what we learned and what we decided to do:
Preparing Data For AI Searches
 One topic of discussion was how projects can prepare data and metadata so they are searchable by AI, since this may be the way of the future.
One topic of discussion was how projects can prepare data and metadata so they are searchable by AI, since this may be the way of the future.
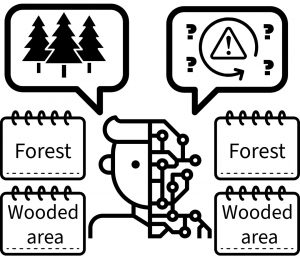
Right now, lots of metadata (information about the data) is language-based. That means additional information about the audio data, like site notes, habitat descriptions, or weather descriptions, might be recorded as words or phrases rather than numbers or standardized codes. While this works well for people reading the data, it makes it harder for AI to process consistently.
Language-based metadata examples from ES
- Site Location notes might say “near cattle pasture.”
- Habitat notes could say “forest,” “woods,” or “woodland.” These all mean the same thing to a person, but could be interpreted differently by AI.
Data Repositories and Preparing for AI
 A data repository is a platform where projects store their data so that it can be preserved and reused by others. If data repositories want improved AI search functionality in the future, they may eventually require that data be submitted in new AI search-ready formats.
A data repository is a platform where projects store their data so that it can be preserved and reused by others. If data repositories want improved AI search functionality in the future, they may eventually require that data be submitted in new AI search-ready formats.
- Zenodo, the platform ES uses to store and share its audio and observation data, is one example of a data repository.
- GitHub, the platform where ES shares its software and code, is another example of a data repository.
 Not all data repositories have decided on standards for AI search. GitHub has introduced AI tools such as Anthropic Claude Sonnet, ChatGPT, and Gemini 2.5 Pro for creating code, but has not yet included AI agents for finding already existing code. Zenodo has not yet incorporated AI tools into its repository, and adding such tools is not in its current development roadmap. With the AI search landscape changing so quickly, it is hard to predict how AI search tools will be implemented in data repositories and how data providers should format their data for AI.
Not all data repositories have decided on standards for AI search. GitHub has introduced AI tools such as Anthropic Claude Sonnet, ChatGPT, and Gemini 2.5 Pro for creating code, but has not yet included AI agents for finding already existing code. Zenodo has not yet incorporated AI tools into its repository, and adding such tools is not in its current development roadmap. With the AI search landscape changing so quickly, it is hard to predict how AI search tools will be implemented in data repositories and how data providers should format their data for AI.
Vector Databases: An AI Search-Friendly Format
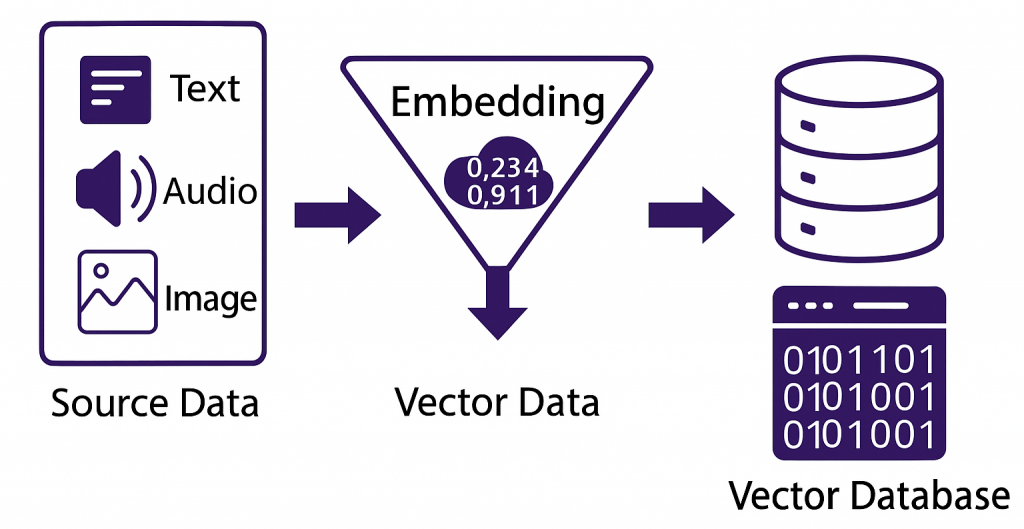 One AI search-friendly option that was discussed is putting each project’s data into a vector database that could be shared with its chosen data repository. A vector database combines data with metadata and also describes that metadata numerically rather than through language and keywords.
One AI search-friendly option that was discussed is putting each project’s data into a vector database that could be shared with its chosen data repository. A vector database combines data with metadata and also describes that metadata numerically rather than through language and keywords.
These numerical metadata descriptions make it easier for AI to:
- Recognize similarities rather than just exact search term matches
- Remember and connect previous inputs
- Understand data in a broader context
Examples of vector database platforms include:
- ChromaDB (Open Source, Python-based) https://github.com/chroma-core/chroma
- Pinecone (Commercial) https://www.pinecone.io/
Zenodo, the repository where ES data is being archived, does not currently have a plan to support vector databases. It is impossible to predict how Zenodo or other online data repositories might incorporate vector databases and what future standards they may require.
ES’s Decision
Creating a vector database is more than what Eclipse Soundscapes can take on right now. It would take more time and resources than the project has and would mean looking for new data repositories or doing extensive work to fit it into Zenodo’s framework.
Still, we’re glad we explored this possibility. Thinking about what AI might mean for scientific data is worthwhile, even if we can’t take it on ourselves. As projects wind down, it helps to keep looking ahead. Our team will carry this knowledge into future efforts, and by sharing it here, the ES community can carry it forward too.
If you want to learn more about vector databases, check out these articles:
- Microsoft’s article: Understanding Vector Databases
- Cloudflare’s article: What is a Vector Database?